MySQL海量数据存储与优化 数据处理与存储支持服务全解析
在当今数据驱动的时代,企业面临着海量数据的存储、处理与优化挑战。MySQL作为全球最流行的开源关系型数据库之一,凭借其稳定性、易用性和丰富的生态,成为许多企业处理海量数据的核心选择。随着数据量的指数级增长,如何高效存储、优化处理并提供可靠的存储支持服务,成为技术团队必须攻克的关键课题。
一、海量数据存储架构设计
- 分库分表策略
- 水平分表:按时间、地域或哈希算法将单表数据拆分到多个物理表中,解决单表数据量过大导致的性能瓶颈。
- 垂直分库:按业务模块将数据库拆分为多个专用数据库,降低单库压力并提升业务隔离性。
- 分片中间件:采用ShardingSphere、MyCat等工具实现透明化分片,平衡开发复杂度与系统性能。
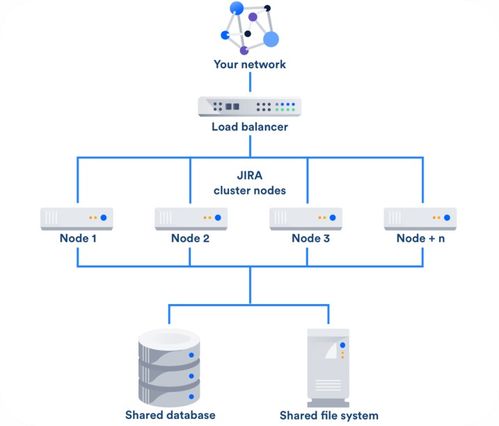
- 分布式存储方案
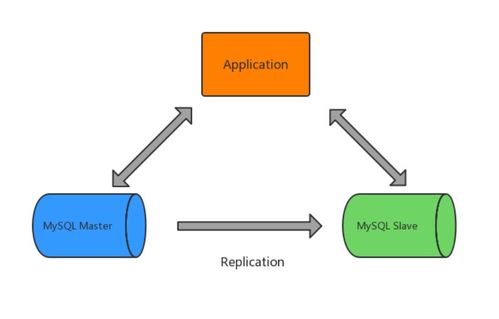
- 主从复制集群:通过读写分离架构,将写操作集中于主库,读操作分散至多个从库,显著提升查询并发能力。
- MGR(MySQL Group Replication):基于Paxos协议实现多主同步,提供高可用与数据强一致性保障。
- 云数据库服务:利用AWS RDS、阿里云RDS等托管服务,自动处理备份、扩展与故障转移。
- 冷热数据分离
- 热数据存储:将高频访问数据存放于SSD或内存优化型实例,确保毫秒级响应。
- 温冷数据归档:通过分区表或外部存储(如OSS、S3)存储历史数据,结合数据生命周期管理自动迁移。
二、数据处理优化核心技术
- 索引智能优化
- 联合索引设计:遵循最左匹配原则,避免冗余索引,利用覆盖索引减少回表查询。
- 自适应哈希索引:针对等值查询频繁场景,启用InnoDB自适应哈希索引提升检索效率。
- 索引下推(ICP):在MySQL 5.6+版本中,将WHERE条件过滤下推到存储引擎层,减少不必要的行扫描。
- 查询性能调优
- 慢查询分析:通过slow_log、Performance Schema定位耗时操作,使用EXPLAIN分析执行计划。
- 批量操作优化:采用INSERT ... ON DUPLICATE KEY UPDATE替代逐条处理,减少网络往返与事务开销。
- 连接池配置:合理设置连接池参数(如maxconnections、waittimeout),避免连接风暴与资源泄漏。
- 事务与锁机制调优
- 事务隔离级别选择:根据业务一致性要求平衡性能,如读提交(RC)级别可减少间隙锁竞争。
- 行锁升级监控:通过informationschema.INNODBTRX表监控长事务,避免锁等待超时。
- 乐观锁应用:在高并发更新场景中使用版本号机制,减少悲观锁带来的性能损耗。
三、存储支持服务体系建设
- 自动化运维平台
- 智能监控告警:集成Prometheus+Grafana实现性能指标(QPS、TPS、慢查询率)可视化与阈值告警。
- 自动备份恢复:制定全量+增量备份策略,利用XtraBackup实现无损在线备份,定期演练灾难恢复流程。
- 版本滚动升级:通过在线DDL工具(pt-online-schema-change)实现无锁表结构变更,最小化业务影响。
- 数据安全与合规
- 透明数据加密(TDE):对静态数据加密存储,结合密钥轮转机制防范数据泄露风险。
- 审计日志记录:启用general_log或企业级审计插件,满足GDPR等合规性要求。
- 数据脱敏服务:在测试环境中使用动态脱敏技术,防止敏感信息外泄。
- 弹性扩展能力
- 自动水平扩展:基于Kubernetes Operator实现MySQL集群弹性伸缩,根据负载动态调整实例数量。
- 存储引擎选择:针对不同场景选用InnoDB(事务支持)、MyISAM(读密集型)或ClickHouse(分析型)引擎。
- 混合存储支持:结合Redis缓存热点数据,使用TiDB处理HTAP混合负载,构建分层存储体系。
四、最佳实践与未来展望
- 实战经验分享
- 某电商平台通过分库分表处理每日亿级订单数据,查询响应时间从秒级降至毫秒级。
- 金融行业采用MGR集群实现跨地域多活,年度可用性达99.99%,RPO≈0。
- 物联网企业结合时间序列分区表,高效管理千亿级设备上报数据,存储成本降低60%。
- 技术演进趋势
- 云原生数据库:Serverless架构实现按需计费与自动弹性,进一步降低运维复杂度。
- AI赋能优化:基于机器学习的索引推荐与参数调优系统(如MySQL Autopilot)将成为标配。
- 多模数据融合:MySQL将与文档存储、图数据库等技术融合,提供统一的数据服务层。
MySQL海量数据存储与优化是一项系统工程,需要从架构设计、查询优化到运维服务进行全面规划。随着技术的不断演进,企业应建立持续优化的数据治理体系,将数据库从“成本中心”转化为“业务赋能平台”,最终在数据洪流中构建坚实、高效、智能的数据基座。
如若转载,请注明出处:http://www.668a2.com/product/35.html
更新时间:2026-03-01 01:35:23